本帖最后由 jiuxin2018 于 2019-5-13 17:27 编辑
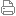
由人工智能研发团队 DeepMind 发表的 AlphaZero 登上最新一期《科学》杂志封面。这已经不是 DeepMind 第一次登上国外权威杂志的封面,每一次 DeepMind 被报导都会获得人工智能学界的一阵欢呼,这次更是如此。同时击败围棋、将棋、西洋棋最强 AI 的AlphaZero ,被认为可能代表着深度学习 AI 的终极解答。 《科学》杂志表示,如果人们想透过一套计算方式去解决多个不同的复杂问题,那么唯一能够达成这目标的办法就是,创造一个自主学习的人工智能系统,让它自行学着去解决问题。而 AlphaZero 办到了。 根据 DeepMind 的介绍,AlphaZero 使用完全无需人工特征、无需任何人类棋谱、甚至无需任何特定优化的通用强化学习算法。举例来说,由于围棋的规则明显和其他棋类如西洋棋、将棋不同,像是围棋的每一子都是完全相同的、且棋盘也是完全对称的。 为了因应围棋的特殊性, AlphaZero 的前身 AlphaGo Zero 便有设计专为围棋使用的特殊计算程序。但 AlphaZero 没有,作为一个「通用型」学习 AI ,AlphaZero 完全仅依靠深度神经网络和美容仪器蒙特卡洛搜索树算法的自我学习。在完全没有输入人类的棋谱、没有输入特别设计的专用计算程序的情况下,只借着自我对弈的不断学习, AlphaZero 就已经能够分别在围棋将棋西洋棋击败了原本的世界最强 AI 。 而且, AlphaZero 打败原本的西洋棋世界最强 AI 只花了 4 小时学习,打败原本的将棋世界最强 AI 只花了 2 小时学习。打败原本的围棋世界最强 AI 只花了 30 小时学习。 AlphaZero 最大的特色就是可以学会并精通不同的棋类竞赛,而且它每一步棋所须计算的可能性变化,比之前的 AI 要来得少许多。换句话说, AlphaZero 并不是去无限量的计算棋盘所有可能性,而是透过自己的深度神经网络分析,专注于小范围的计算。 这样的「思考模式」,其实正和一般人类棋士无异。西洋棋前世界冠军Garry Kasparov 就表示, AlphaZero 的下棋风格灵活多变,「和我很像!」,且不同于其他 AI 程序倾向保守的先求立于不败, AlphaZero 非常具有侵略性,更喜欢冒险。传统的人工智能程序在下棋时,凭借强大计算能力很少犯错,但在面对不清楚「该计算什么」的局面时,便容易出现失误。反观 AlphaZero ,它呈现出的是一种「感觉」、「洞察」,一种对棋盘上局势发展的直觉。 曾和 AlphaGo Zero 对奕的围棋棋士李世石便说过「我改变了看法, AlphaGo Zero 不只是机器,它具有创造性」。而现在同时精通围棋将棋西洋棋的 AlphaZero ,显然拥有更强更灵活的创造能力。 过往的人工智能程序,往往只能精通专一领域,只能处理特定情境的问题。但 AlphaZero 不同,它能够适应各种规则。这让人相信,未来可以将这深度自主学习的 AI 能力,运用在其他问题上。比如说, DeepMind 团队开发的最新家族成员 AlphaFord ,便是投入在学习基因序列的蛋白质结构相关问题。假如在此领域 AlphaFord 也能获得惊人成就,那可不同于在棋类竞赛赢过对手,将会真正替人类社会带来巨大改变。
| 







 发表于 2019-5-13 17:26
发表于 2019-5-13 17:26

 收藏
收藏 分享
分享 顶
顶 踩
踩 提升卡
提升卡 喧嚣卡
喧嚣卡 变色卡
变色卡